Kunskapsgrafen är ett verktyg som ger dig en snabb överblick
över dina kunskapsluckor. Genom att analysera resultaten av dina
genomförda frågesessioner kan plattformen ta fram en
kunskapsnivå för de områden som ingår i dina studier.
Kunskapsnivån visualiseras med hjälp av en graf, med
funktionalitet för att filtrera ut både styrkor och svagheter.
För att kunna dra slutsatser presenterar vi även
konfidensintervallet för varje uppskattning. Om du endast har
besvarat ett fåtal frågor finns det inte tillräckligt med data
för att dra en definitiv slutsats. Ju fler frågor du besvarar,
desto mindre är konfidensintervallet och sannolikheten ökar för
att uppskattningarna stämmer.
Algoritmen för att estimera kunskapsnivå för en viss användare
bygger på att användaren dels besvarar frågor regelbundet, samt
även att en större mängd frågor besvaras. Besvarade frågor som
tas med i beräkningen till kunskapsnivå är enbart de som har
besvarats inom 45 dagar samt de 100 senaste frågorna. Bäst
estimering, dvs bäst träffsäkerhet, av kunskapsnivå får man
alltså om man har besvarat minst 100 frågor de senaste 45
dagarna.
Vill du veta mer om hur uträkningen görs? Läs gärna vidare!
Sannolikheten för ett visst utfall
Låt oss säga att en användare registrerar sig på hypocampus.se
och börjar med att svara på ett antal frågor. Den första dagen
besvarar användaren fem frågor, varav två med rätt svar. Hur
beräknar man kunskapsnivån hos eleven inom det relevanta
området? Det enklaste sättet att förutsäga sannolikheten att
besvara en fråga rätt är att dividera antalet frågor som
besvarats rätt med det totala antalet frågor.
k = 2/5 = 0,4
Uppskattningen är bra men tar inte hänsyn till antalet besvarade
frågor. Det finns många olika kunskapsnivåer som skulle kunna ge
ovanstående resultat. För att precisera beräkningen kan vi skapa
en graf som visar sannolikheten att få ovanstående resultat
baserat på den faktiska kunskapsnivån.
Diagrammet visar att kunskapsnivå 0,4 är den mest sannolika,
men det finns ett ganska brett spektrum av världen för
kunskapsnivå som skulle kunna ge samma resultat. Genom att
tillhandahålla ett konfidensintervall får vi ett mått på
noggrannheten i vår uppskattning.
Så, vilket intervall ska vi använda för att ge 95 % säkerhet
att den faktiska kunskapsnivån ingår i intervallet?
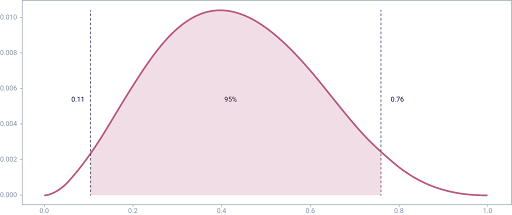
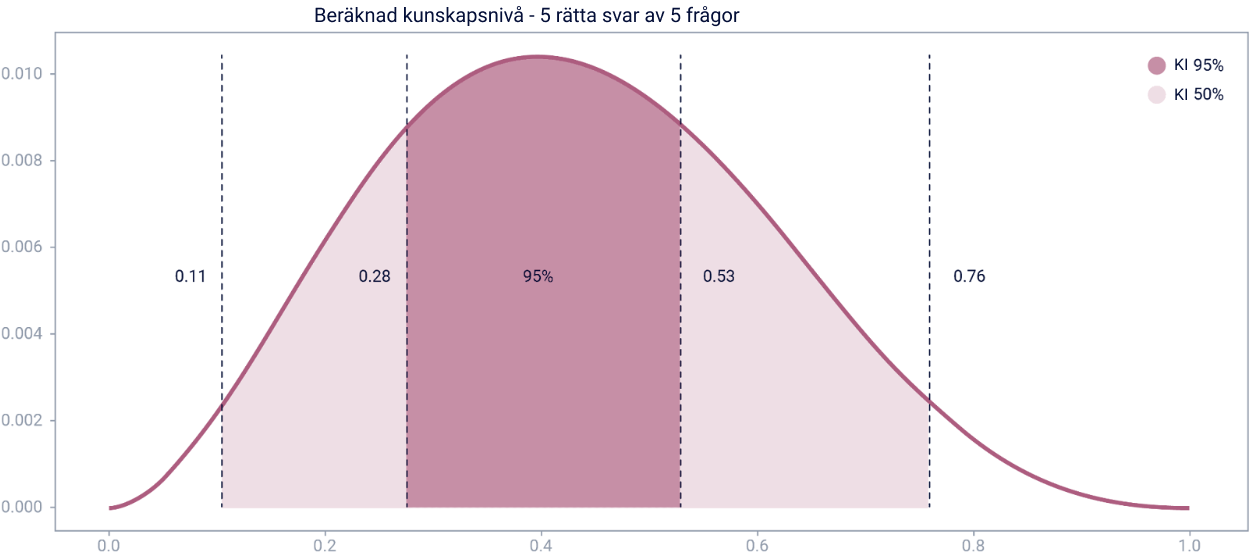
Att döma av grafen kan vi med 95% säkerhet säga att den
faktiska kunskapsnivån ligger mellan 0,11 och 0,76, med ett
konfidensintervall på 50%.
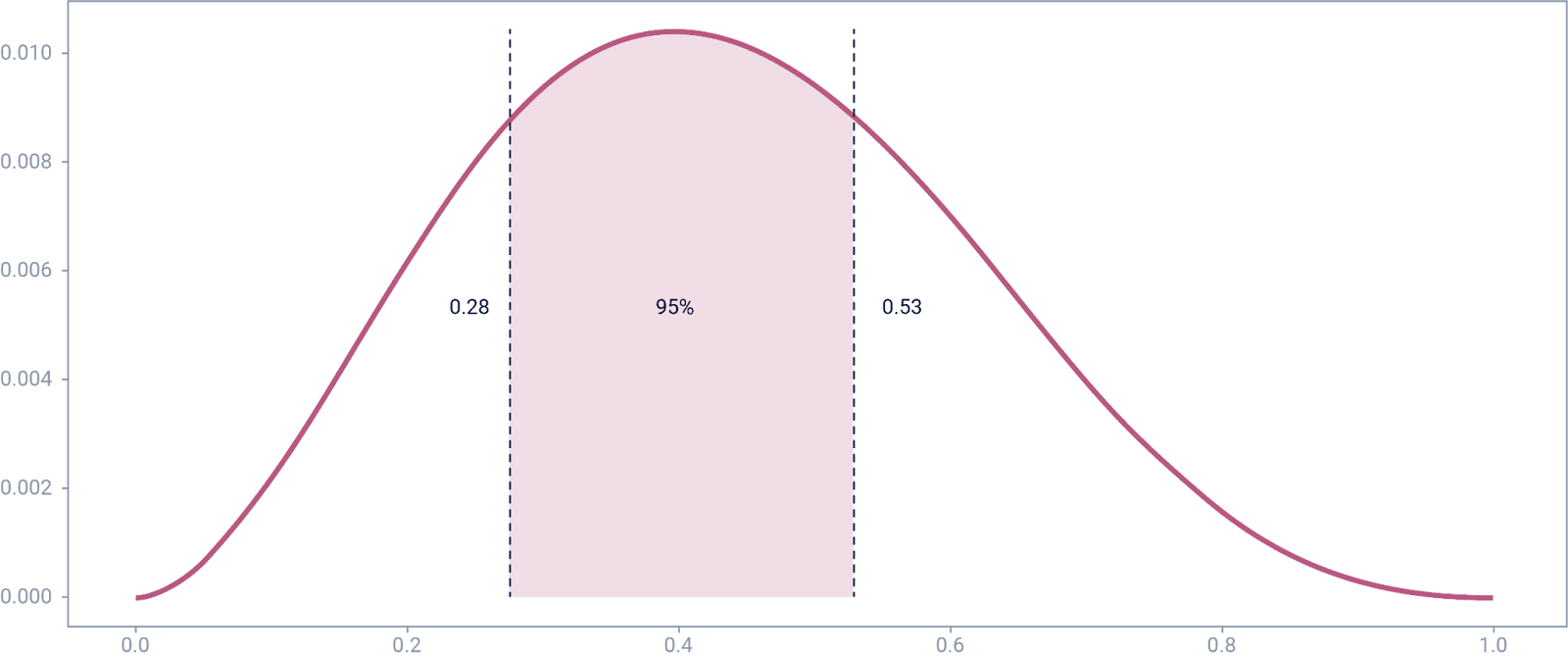
Med 50% träffsäkerhet kan vi säga att kunskapsnivån ligger
mellan 0,28 och 0,53. Resultatet är baserat på 5 besvarade
frågor.
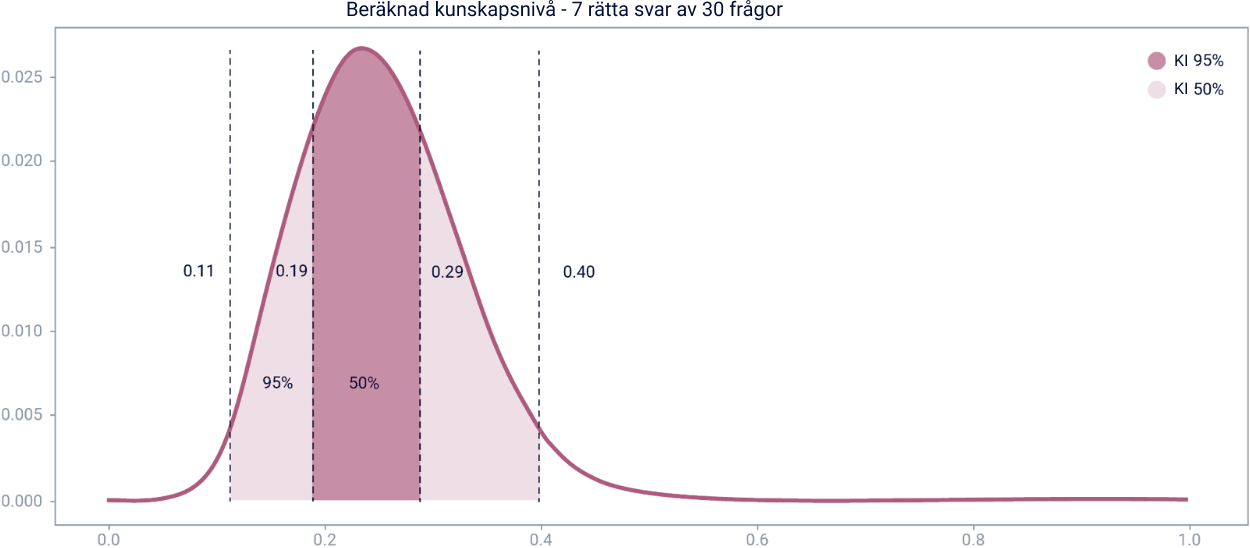
Låt oss säga att samma användare fortsätter att besvara
frågor. Efter en vecka har 30 frågor besvarats, varav 7 med
rätt svar. Grafen skulle nu se ut så här:
Konfidensintervallet är mindre. Vi kan med 50% säkerhet säga
att kunskapsnivån ligger någonstans mellan 0,19 - 0,29 och
med 95% säkerhet säga att kunskapsnivån mellan 0,11 och
0,40.
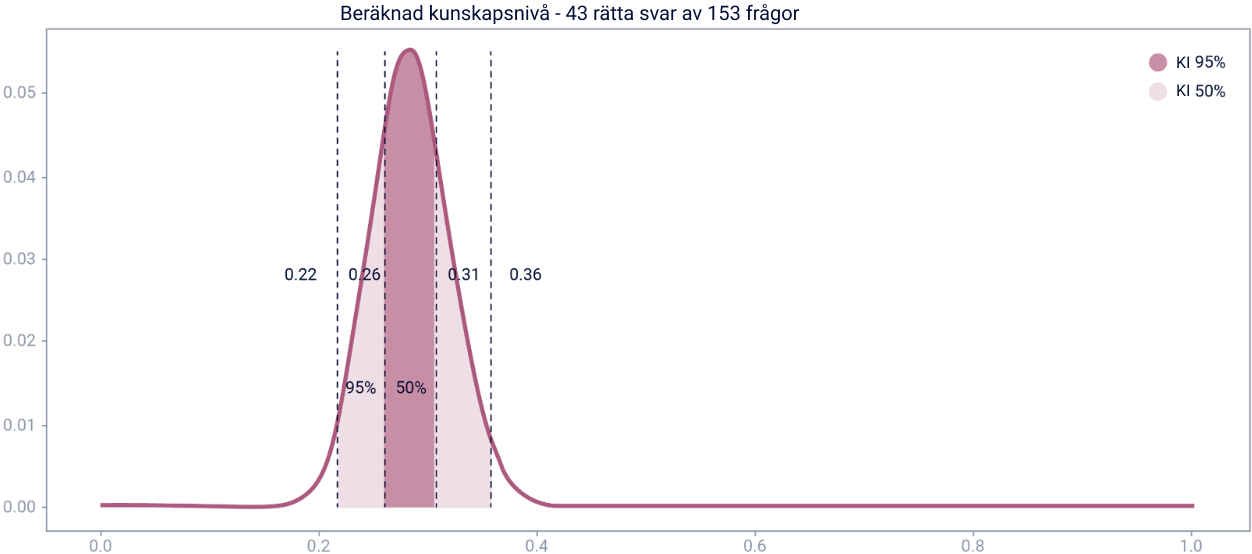
Eleven fortsätter att använda plattformen i en månad och
besvarar noll till tio frågor per dag. Låt oss säga att 153
frågor har besvarats totalt varav 43 med rätt svar. Hur ser
grafen ut nu?
Vi vet nu med 50% säkerhet att kunskapsnivån ligger någonstans
mellan 0,26-0,31 och med 95% säkerhet att kunskapsnivån ligger
någonstans mellan 0,22 och 0,36. Vilka slutsatser kan vi dra av
detta? I början, när beräkningarna endast är baserade på svaren från
ett fåtal frågor, kommer kunskapsnivån att ha ett brett
konfidensintervall. Säkerheten för den faktiska siffran som
presenteras kommer att vara låg. För varje ytterligare fråga som
besvaras kommer konfidensintervallet att krympa och sannolikheten
att uppskattningen är korrekt öka.
Ett exempel
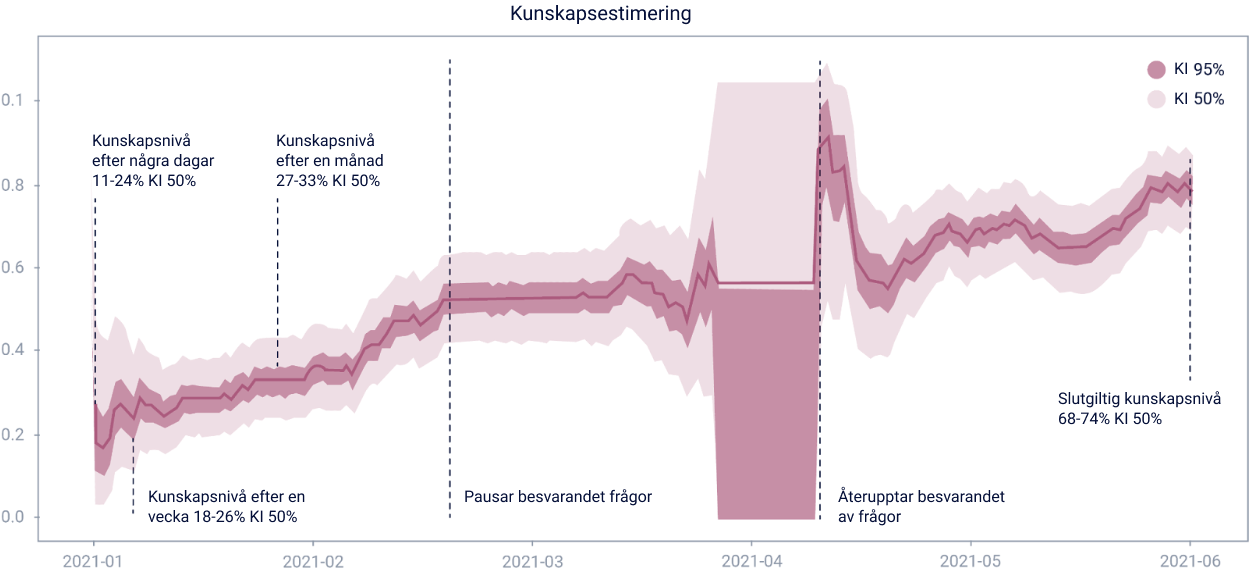
En användare studerar sex månader på plattformen. Under
studietiden ökar kunskapsnivån från 0,3 till 0,7.
Varje dag besvaras en till tio frågor. Sannolikheten att
frågorna besvaras rätt är densamma som kunskapsnivån den dagen.
Vid uppskattning av kunskapsnivå räknas endast de senaste 100
svaren in, för att säkerställa att grafen speglar användarnas
nuvarande kunskapsnivå. Av dessa 100 svar filtreras de som är
äldre än 45 dagar bort.
Eleven i exemplet besvarar inga frågor under en tvåmånaders
period. Efter sex månader ser grafen ut så här.